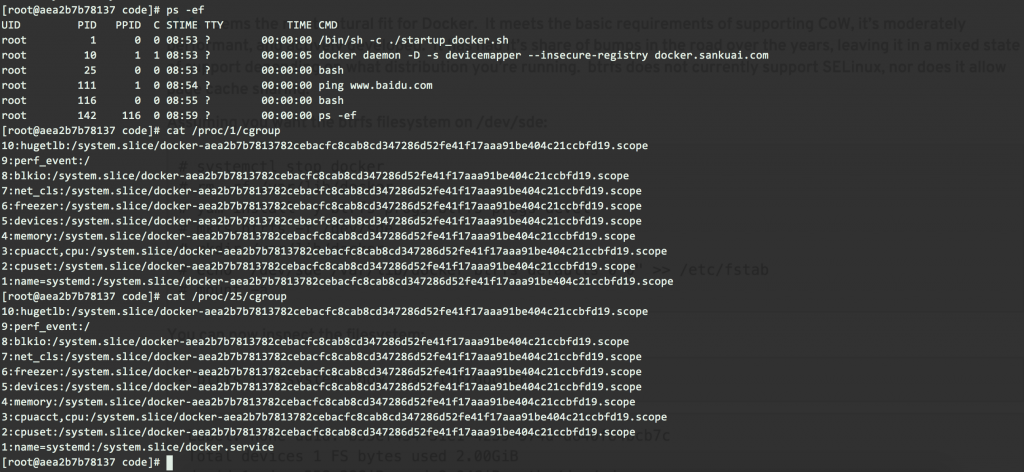
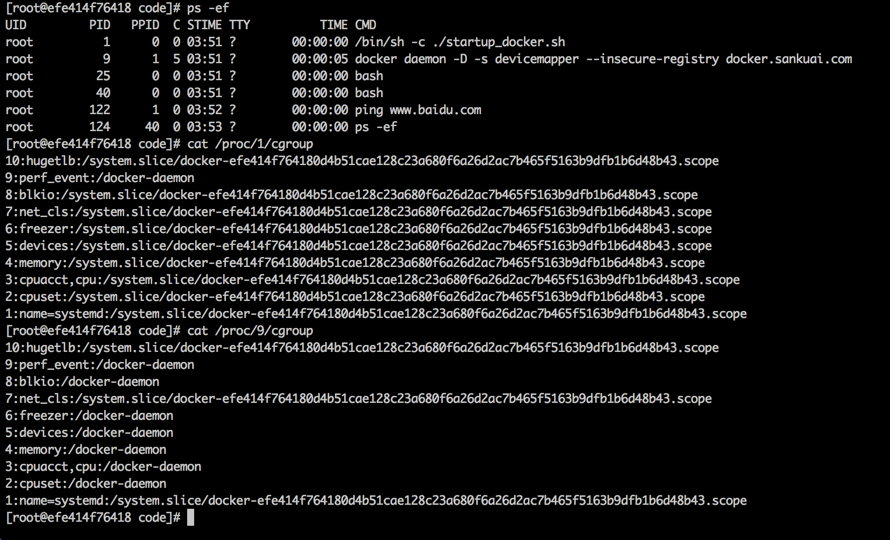
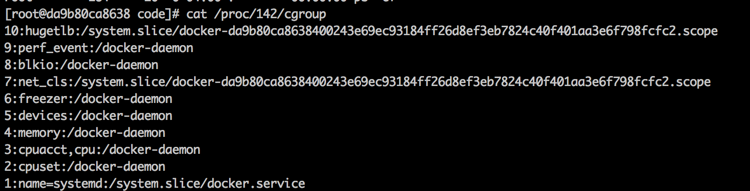
首先复习一下Kubernetes内的对象类型
- Node:运行kubelet(古代叫minion)的计算机
- Pod:最小调度单位,包含一个pause容器、至少一个运行应用的容器
- RC:复本控制器,用于保持同类Pod的并行运行的数量
- Svc:暴露服务的可访问通信接口
对象之间的通信关系
|
客户端
|
服务器
|
访问方式
|
|---|---|---|
| master | kubelet | Node的10250/TCP端口。Node报到后,Master得知Node的IP地址 |
| kubelet
& kube_proxy |
apiserver | master:8080/TCP HTTP
配置文件写明master地址 |
| kubectl命令行 | apiserver | localhost:8080/TCP或命令行参数指定 |
| other ALL | apiserver | ClusterIP_of_kubernetes:443/TCP HTTPS
上述IP和端口号通过环境变量通知到容器 需要出示身份信息 kubernetes是一个ClusterIP模式的Service。参见下面详述 |
| pod | pod | 跨Node的多个pod相互通信,需要通过overlay network,下面详述 |
| ALL | service | 三种模式,下面详述 |
overlay network
kubernetes不提供pod之间通信的功能,需要装额外的软件来配合。我选的是出自CoreOS的flannel软件:
flannel是专门为docker跨Host通信而设计的overlay network软件,从ETCd获取配置,提供对docker网络参数进行配置的脚本,使用UDP、VXLAN等多种协议承载流量。
经实验,flannel在办公云(新)上会导致kernel panic
flannel配置
在/etc/sysconfig/flanneld 配置文件中写好etcd的地址
用etcdctl mk /coreos.com/network/config 命令将下列配置写入etcd:
{"Network": "172.17.0.0/16","SubnetLen": 24,"Backend": { "Type": "vxlan", "VNI": 7890 } } |
Network代表flannel管理的总的网络范围;SubnetLen是其中每个节点的子网掩码长度;Backend规定了各节点之间交换数据的底层承载协议。
再各Node执行 systemctl start flanneld 启动服务。
flannel对docker作用的原理
flannel 并非“神奇地”对docker产生作用。
查看/usr/lib/systemd/system/flanneld.service配置文件可知,在flanneld启动成功之后,systemd还会去执行一次/usr/libexec/flannel/mk-docker-opts.sh脚本,生成/run/flannel/docker环境变量文件。
flannel的RPM中包含的 /usr/lib/systemd/system/docker.service.d/flannel.conf ,作为docker服务的配置片段,引用了上述环境变量文件 /run/flannel/docker ,故 flannel 必须在 docker 之前启动,如果在docker已经运行的情况下启动flannel,则docker也必须重启才能生效。。通过 systemctl status docker 可以看到
# systemctl status dockerdocker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled) Drop-In: /usr/lib/systemd/system/docker.service.d └─flannel.conf Active: active (running) since 一 2015-12-14 15:53:06 CST; 19h ago Docs: http://docs.docker.com Main PID: 149365 (docker) CGroup: /system.slice/docker.service └─149365 /usr/bin/docker daemon --selinux-enabled -s btrfs --bip=172.17.33.1/24 --mtu=1450 --insecure-registry docker.sankuai.com |
flannel作用于docker,最终表现为设置了其–bip 参数,也就是 docker0 设备的IP地址。如重启时失败,可以用ip addr命令删除docker0上的IP然后再重新启动docker服务。
另外,flannel会在各节点上生成一个名为flannel.7890的虚拟接口(其中7890就是上面配置文件里的VNI号码)其掩码为/16,但IP和docker0的IP地址相近。这种配置生成的路由表如下:
即:与172.17.33.0/24 通信,通过docker0;与172.17.0.0/16 通信(不含172.17.33.0/24),通过flannel.7890 发往overlay network
Docker和容器的网络
用ip link add vethX peer name vethY命令添加一对虚拟以太网接口。
veth和普通eth接口的区别在于:veth一次就要配置一对,这一对veth接口有背对背的隐含连接关系,可以通过tcpdump和ping来验证。
然后把其中一个网卡移到容器的namespace里,另一个加入docker0 bridge,即完成将容器连接到docker0 bridge的工作。
查看namespace内情况的方法,请参见https://gist.github.com/vishvananda/5834761
Kubernetes Pod的网络配置
一个Pod最少包含两个容器,其中一个叫pause,它什么都不敢,只“持有”IP地址。通过docker inspect可以看到:
[{ "Id": "2b36d6cb2f2d822473aa69cacb99d8c21e0d593a3e89df6c273eec1d706e5be8", "NetworkSettings": { "Bridge": "", "EndpointID": "2c1e17f3fd076816d651e62a4c9f072abcc1676402fb5eebe3a8f84548600db0", "Gateway": "172.17.33.1", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "HairpinMode": false, "IPAddress": "172.17.33.2", "IPPrefixLen": 24, "IPv6Gateway": "", "LinkLocalIPv6Address": "", "LinkLocalIPv6PrefixLen": 0, "MacAddress": "02:42:ac:11:21:02", "NetworkID": "6a23154bd393b4c806259ffc15f5b719ca2cd891502a1f9854261ccb17011b07", "PortMapping": null, "Ports": {}, "SandboxKey": "/var/run/docker/netns/2b36d6cb2f2d", "SecondaryIPAddresses": null, "SecondaryIPv6Addresses": null }, "HostConfig": { "NetworkMode": "default", "IpcMode": "", }] |
而真正运行应用的那个容器,网络配置则是这样:
[{ "Id": "eba0d3c4816fd67b10bcf078fb93f68743f57fa7a8d32c731a6dc000db5fafe8", "NetworkSettings": { "Bridge": "", "EndpointID": "", "Gateway": "", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "HairpinMode": false, "IPAddress": "", "IPPrefixLen": 0, "IPv6Gateway": "", "LinkLocalIPv6Address": "", "LinkLocalIPv6PrefixLen": 0, "MacAddress": "", "NetworkID": "", "PortMapping": null, "Ports": null, "SandboxKey": "", "SecondaryIPAddresses": null, "SecondaryIPv6Addresses": null }, "HostConfig": { "NetworkMode": "container:2b36d6cb2f2d822473aa69cacb99d8c21e0d593a3e89df6c273eec1d706e5be8", "IpcMode": "container:2b36d6cb2f2d822473aa69cacb99d8c21e0d593a3e89df6c273eec1d706e5be8", }] |
注意对比NetworkMode和IpcMode的值,后者的NetworkMode和IpcMode的值为前者的Id。
Kubernetes这种设计,是为了实现单个Pod里的多个容器共享同一个IP的目的。除了IP以外,Volume也是在Pod粒度由多个容器共用的。
Kube-Proxy服务
kubernetes各节点的kube-proxy服务启动后,会从apiserver拉回数据,然后设置所在机器的iptables规则。
对于如下的svc:
# kubectl describe svc/mysql
Name: mysql
Namespace: default
Labels: name=mysql
Selector: name=newdeploy
Type: ClusterIP
IP: 10.16.59.77
Port: <unnamed> 3306/TCP
Endpoints: 172.17.29.35:3306
Session Affinity: None
No events.
生成的iptables规则如下:
-A PREROUTING -m comment –comment “handle ClusterIPs; NOTE: this must be before the NodePort rules” -j KUBE-PORTALS-CONTAINER
-A PREROUTING -m addrtype –dst-type LOCAL -m comment –comment “handle service NodePorts; NOTE: this must be the last rule in the chain” -j KUBE-NODEPORT-CONTAINER
-A OUTPUT -m comment –comment “handle ClusterIPs; NOTE: this must be before the NodePort rules” -j KUBE-PORTALS-HOST
-A OUTPUT -m addrtype –dst-type LOCAL -m comment –comment “handle service NodePorts; NOTE: this must be the last rule in the chain” -j KUBE-NODEPORT-HOST
-A KUBE-PORTALS-CONTAINER -d 10.16.59.77/32 -p tcp -m comment –comment “default/mysql:” -m tcp –dport 3306 -j REDIRECT –to-ports 53407
-A KUBE-PORTALS-HOST -d 10.16.59.77/32 -p tcp -m comment –comment “default/mysql:” -m tcp –dport 3306 -j DNAT –to-destination 10.16.59.13:53407
(之所以在PREROUTING和OUTPUT设置相同的规则,是为了匹配从外部来的访问和发自本机的访问两种情况)
上述规则把访问 10.16.59.77:3306/TCP的请求,转到了本机的53407端口。用lsof检查可以发现该端口为kube-proxy进程。kube-proxy在各机器上会选择不同的端口以避免冲突。kube-proxy收到请求后,会转发给Service里定义的Endpoints
1.1版本开始,新增–proxy-mode=iptables模式,直接按相同比例把请求DNAT到指定的endpoint去。
Kubernetes Service的三种模式
- ClusterIP模式
- NodePort模式
- LoadBalancer模式
ClusterIP模式
生成一个 只在本cluster内有效的IP:port 组合,也就是仅对内暴露该服务。生成的IP范围由apiserver的–service-cluster-ip-range参数规定。
将生成的IP绑在一台运行着kube-proxy的机器上时,也可以对外提供服务。1.1版本的kube-proxy –proxy-mode=iptables时不能支持将clusterIP绑在Node上对外服务的做法。
NodePort模式
在所有Node上,用相同的端口号暴露服务。如Node的IP对cluster以外可见,则外部也可以访问该服务。
LoadBalancer模式
通知外部LoadBalancer生成 外部IP:port组合 ,并将请求转发进来,发给NodeIP:NodePort们。该行为听起来会把数据转发很多次。
该功能需要外部环境支持。目前GCE/GKE、AWS、OpenStack有插件支持该模式。