
术语约定:
- Host:外层运行操作系统的机器
- 外层daemon:Host上的docker daemon
- 外层容器:外层daemon下辖的container,镜像启动时加–privileged参数。这个镜像的准备步骤是从docker下载当前1.9.1版安装(并固化到镜像里)CMD是一个脚本,先启动带debug选项的docker daemon 并放后台运行,然后pull并运行centos:7 一次,最后开启一个不停ping的命令,保持容器持续运行。通过docker exec 进入另行执行docker run命令测试内层是否可以正常启动
- 内层daemon:外层容器里的docker daemon
- 内层容器:内层daemon下辖的container
宋传义最近几周在尝试docker in docker,报告过几个问题,我在这里简要记录一下。因为在此docker in docker研究过程中我只是顾问的身份,并非主研人员,所以记述内容难免有缺乏背景介绍、阶段靠后等问题。宋传义报告的大量现象都是“最后一句错误信息”,但我的工作方式是从“第一条错误信息开始看”。
启动内层docker daemon时报告缺cgroup mount
宋传义报告在1.9上可以成功的在外层容器里运行内层的docker daemon,但1.7的报告缺cgroup mount。检查发现,Docker 1.7 并不会给内层容器 mount /sys/fs/cgroup/* 目录。只需要手工补mount即可混过去,满足启动docker daemon的需求。
在Docker 1.8.0的changelog里 Runtime 小节记述了这个变动:
- Add cgroup bind mount by default
因此1.8.0以后都是可以的。CentOS 7.1.1503 早先版本带的是 1.7.1 后续升级到 1.8.2。后经催促,公司内网的安装源更新到新版本 。
不过1.8.2 RPM的docker-storage-setup脚本有问题 https://bugs.centos.org/view.php?id=9787 在未启用LVM的情况下会直接报错退出,无法从 /etc/sysconfig/docker-storage-setup 生成 /etc/sysconfig/docker-storage 配置文件。所以建议手工维持这俩文件的一致性。
在外层容器里启动内层容器时报告缺/sys/fs/cgroup/docker.service
这个故障,宋传义描述为“只有rz-ep17上docker in docker运行正常,其它机器均失败”。我尝试了一下,其它机器也不是全都失败,只是失败概率极高,偶尔还能遇到stack overflow;rz-ep17也不是每次都成功,但成功率极高。宋传义报告的故障现象为 docker run 失败,错误信息为 umount shm 和 umount mqueue失败。
首先双人交叉检查故障机和正常机的软件版本,发现Host内核、Docker外层daemon版本均精确一致、命令行精确一致;内层docker不管什么版本都能重现故障。听起来似乎是灵异现象。
尝试用fatrace、inotify-tools检查,发现fatrace在打开fanotify之后,IO事件发生后即收到File too large错误信息退出;而inotify直接就没动静。看起来这俩工具还不兼容container环境。
scytest 这个镜像启动时会在后台启动 start_docker.sh 它会在后台运行内层daemon。
在这个daemon环境下,用 docker run -ti 启动内层容器,则基本可以确保损毁当前运行的内层docker daemon,后续所有次数启动内层容器均会出现umount shm和umount mqueue失败的问题。后续我们发现是上次daemon出错时未能及时umount掉device-mapper设备,虽然下次daemon启动时会尝试清理,但还是没清理干净。手工umount掉/var/lib/docker/container/***ID***/{shm,mqueue} 即可修复。期间还尝试在外层容器里执行dmsetup remove_all 结果发现删除了容器里的device mapper之后,Host的device mapper设备节点漏进来了,是个安全隐患。
在这个daemon环境下,用 docker run -d 启动内层容器则大概率会成功。
如果kill掉start_docker.sh启动的docker daemon,手工在docker exec bash的命令行上另启动一个daemon,则一定出/sys/fs/cgroup/docker.service的问题。
于是问题逐渐清晰起来。
错误信息的文件名 docker.service 看起来“比较像systemd的命名风格”,所以我找了一下,发现在Host的cgroup目录里 /sys/fs/cgroup/systemd.slice/有个docker.service目录,但外层容器内的cgroup并没有这个。
搜源代码也搜不到docker.service 这个字符串,于是只能判定为该路径是从外部获取并拼装起来的。考虑到命令行精确一致,我又去看了看环境变量,也没有发现相关内容。
凝神定志,用重量级武器strace -f 跟踪内层docker daemon,记录下其文件访问行为,并比对错误信息,可以清晰的看到准备容器文件系统内容、mount、准备容器的cgroup环境、运行程序、失败、清理现场的过程,而且发现对 /sys/fs/cgroup/docker.service 的访问是由 内层daemon调用native exec driver 执行的,还未运行到启动容器内程序的步骤,也就是说,访问的是 外层容器内的/sys/fs/cgroup/docker.service 而不是 内层容器内的该文件。native exec driver目前是libcontainer/runc的一部分。我去GitHub搜源码,偶尔看到在https://github.com/opencontainers/runc/blob/3317785f562b363eb386a2fa4909a55f267088c8/libcontainer/cgroups/utils.go 中有分别读 /proc/1/cgroup 和/proc/self/cgroup 的两个函数,顿时敏感的意识到root cause就在这里。我赶紧去核对,发现 从CMD/ENTRYPOINT启动的start_docker.sh及其子进程docker daemon、子进程ping的/proc/<PID>/cgroup内容最后一行,和手工docker exec 进去执行的所有命令的该文件的最后一行内容不同:
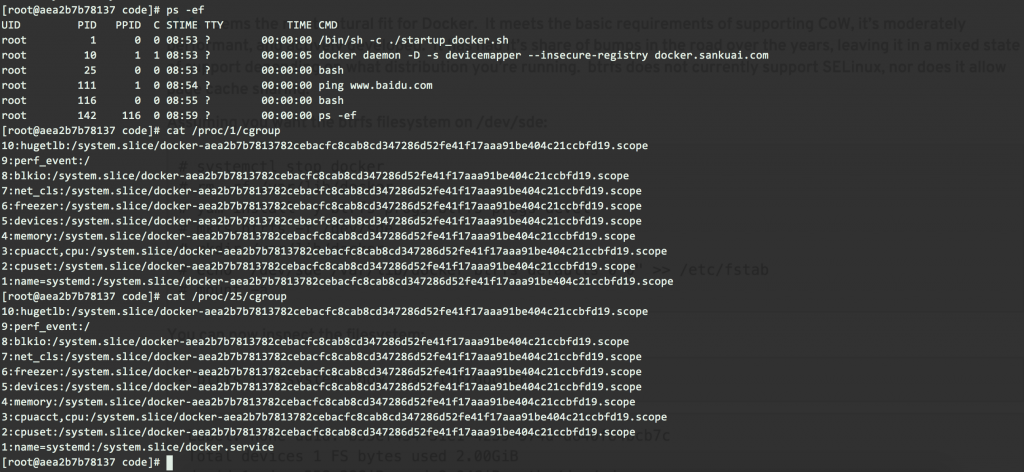
上述路径前面拼上/sys/fs/cgroup/systemd/即为Host上的路径。
看起来应该是由于docker run设置了容器的cgroup环境,所以容器内原生的进程都基础此设置;而docker exec没有这个初始化过程,只是直接送一个进程在容器里执行,所以不同。
根据这个结论,宋传义进行了回归测试,终于可以100%重现失败过程,近100%重现成功过程(部分失败由于代码质量引起stackoverflow)
启动内层容器时报告缺/sys/fs/docker-daemon
错误信息 Error response from daemon: Cannot start container 8aa10e0596282a11b7d841f25355426e9a5e395cb980cf66ec89c9d1a439ae4d: [8] System error: mkdir /sys/fs/docker-daemon: no such file or directory
和上面那个故障相关
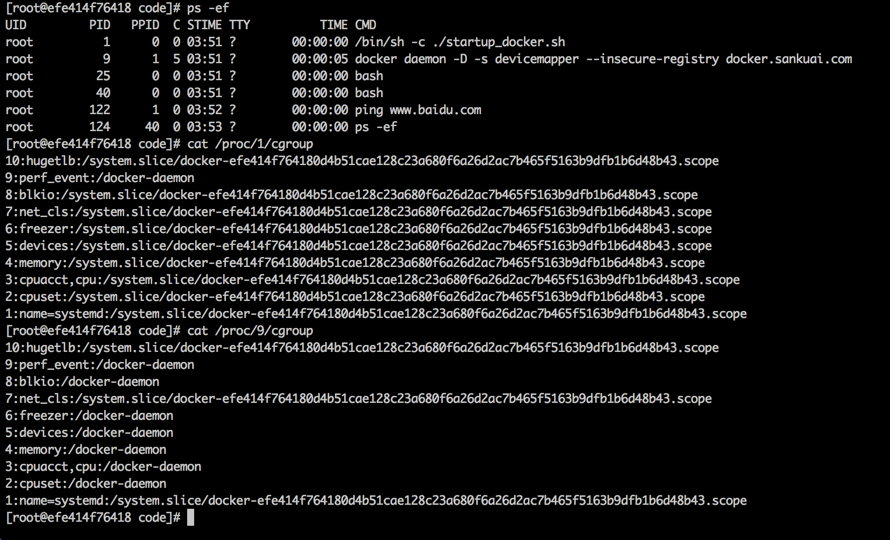
但因为mkdir: cannot create directory ‘/sys/fs/docker-daemon’: No such file or directory (/sys/fs/ 不是一个tmpfs而是/sys/的一部分;对比/sys/fs/cgroup/ 是个tmpfs可以随便写入)所以此问题无解
奇怪的是,我手工启动一个 daemon 其状态如下:
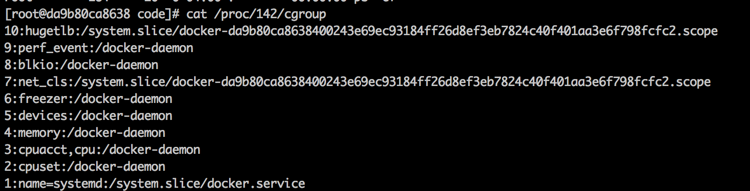
结果一样,还是出docker-daemon目录的错误。
可能这就是宋传义在CMD docker daemon和EXEC docker daemon之间来回切换的原因吧?
重启rz-ep16,然后查看,Host上docker服务刚启动时cgroup为
10:hugetlb:/
9:perf_event:/
8:blkio:/
7:net_cls:/
6:freezer:/
5:devices:/
4:memory:/
3:cpuacct,cpu:/
2:cpuset:/
1:name=systemd:/system.slice/docker.service
启动一个–privileged容器之后变成
10:hugetlb:/
9:perf_event:/
8:blkio:/system.slice/docker.service
7:net_cls:/
6:freezer:/
5:devices:/system.slice
4:memory:/system.slice
3:cpuacct,cpu:/system.slice/docker.service
2:cpuset:/
1:name=systemd:/system.slice/docker.service
这个看起来和一直伟光正的rz-ep17相同,且随后的实验都完全成功。
经实验,发现docker被kubelet依赖启动的时候,/proc/<PID>/cgroup 文件中perf_event、freezer、cpuset三行会是/docker-daemon;docker独立启动时则为/ 这样的正确内容。但这俩服务有强关联:systemctl restart docker重启还是错误内容;systemctl stop再start docker成功,但会导致kubelet服务停止。
外层容器首次yum会失败
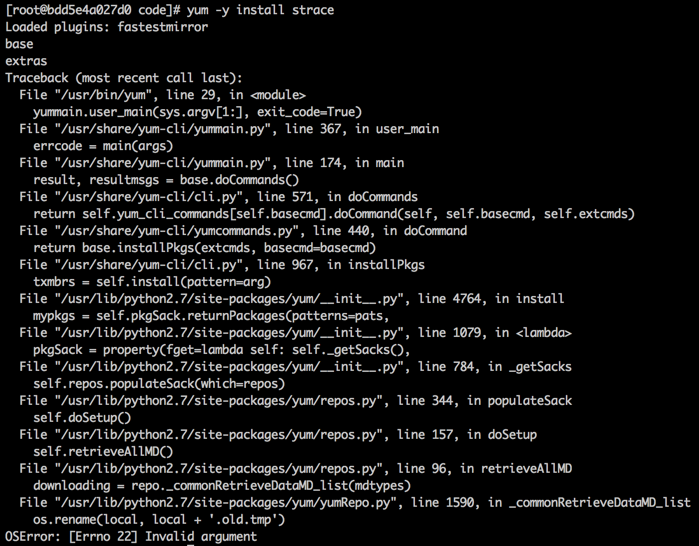
稳定重现,原因不明。第二次就没事了
结论
- 看错误信息要看第一条,而不是最后一条
- 运维相关工具是检查不熟悉程序的行为的利器
- 容器内和操作系统上的运行环境差异较大,除了fatrace\inotify失败,以后可能还会遭遇其它兼容性问题
- Docker的坑还很多,尚处于初期开发阶段,变动很大,质量较差
- 我们对 cgroup 的认识还太粗浅
- 我们对devicemapper完全无认知
- 编译型语言调试比较困难