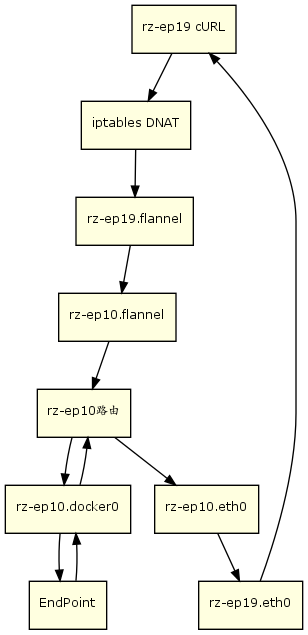
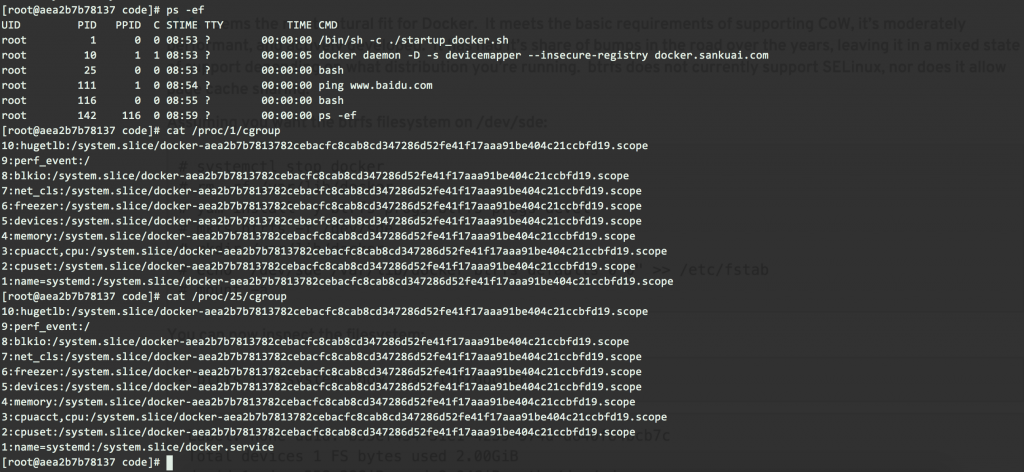
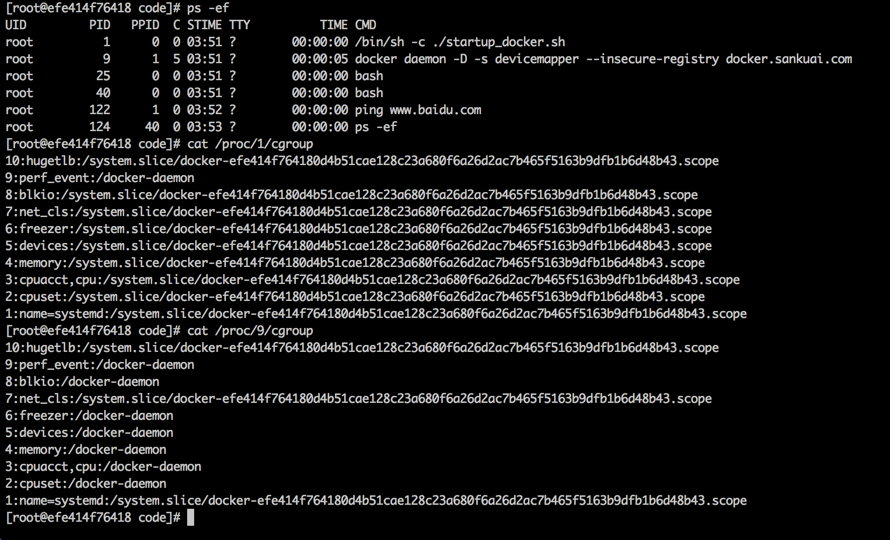
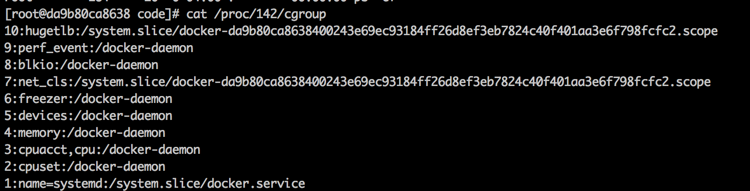
本讨论均基于Sentry 7.7版本
插件机制
自带插件 src/sentry/plugins/ 每插件一个目录
自带插件loader:src/sentry/conf/server.py 里的INSTALLED_APPS tuple
外装插件loader:utils/runner.py 里的 install_plugins()函数,对iter_entry_points()遍历并将其加入INSTALLED_APPS tuple中
外装插件注册:插件的setup.py里执行注册entry_points的过程。例https://github.com/getsentry/sentry-groveio/blob/master/setup.py
import pkg_resources
for ep in pkg_resources.iter_entry_points('sentry.apps'):
print str(ep)
for ep in pkg_resources.iter_entry_points('sentry.plugins'):
print str(ep)
|
sentry-jira插件
插件基本配置
每Project分别配置,需要输入jira的instance URL、用户名和密码。以上内容base64存在数据库sentry_projectoptions表里 where `key` like ‘jira%’
配置用户名密码之后,选择Sentry project关联到哪个JIRA Project,保存设置,并Enable Plugin即可。
Due Date问题
在Sentry Event页面右边点击Create JIRA Issue进入创建页面。但下面Due Date总提示Operation value must be a string 。
也就是说,如果不改sentry-jira插件,就无解。所以我提交了pull request https://github.com/thurloat/sentry-jira/pull/71
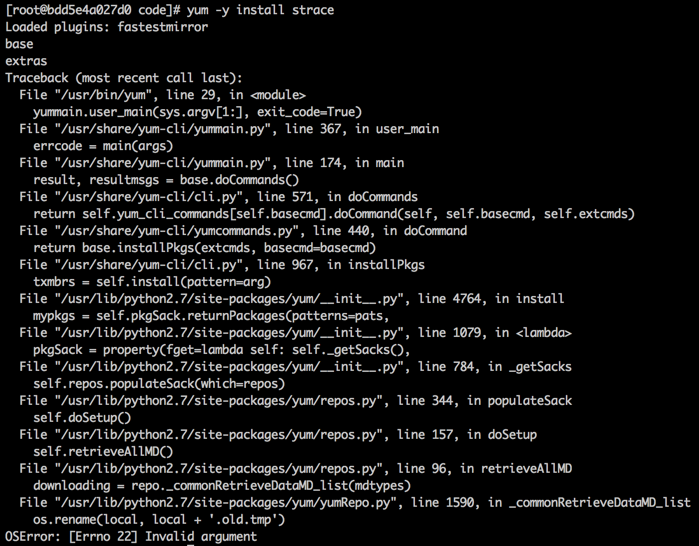
5日下午突然发现,目前线上Sentry 6.4.4的duedate显示为django的SelectDateWidget,而不像我自己的测试装Sentry 7.7一样直接用文本框。经过仔细对比,发现ops-sentry01上的sentry-jira插件是修改过的版本,forms.py文件class JIRAIssueForm新增了一段
|
144
145
146
147
148
149
150
151
|
duedate = forms.DateField(
label="duedate",
widget=SelectDateWidget(),
initial=datetime.datetime.now(),
required=True
)
|
但这段代码没在公司的git库里保存,我就做了tree diff另外保存了。
SSO集成
厂家SSO讨论:https://github.com/getsentry/sentry/issues/1372
新版Sentry有auth backend基类https://github.com/getsentry/sentry/tree/master/src/sentry/auth/
SENTRY_FEATURES['organizations:sso']改为True可以开启Auth页面,设置sso。
目前,我参考sentry-sso-google写出来的sentry-sso-sankuai放在公司内网git库。
SENTRY_SINGLE_ORGANIZATION=True会导致/auth/login/ 跳转到 /auth/login/org_slug/ ,从而无法登录非SSO的用户(如系统自带的名为sentry的超级用户)。所以我在staging环境里关闭了这个参数。
Organizations
当SENTRY_SINGLE_ORGANIZATION=False时,utils/runner.py加载配置之后会将SENTRY_FEATURES[‘organizations:create’]强制改为False,从而禁用了右上角新创建Organization的“加号”链接。如果在此状态下删除了最后一个Organization,则其中的Team会变成游离状态,只能改掉参数重启服务重新创建org了,而且重建之后某种情况下会导致游离状态的Team丢失。切记不要删除Organization!!
根据getsentry原厂GH-1372号issue,每个Organization只能开启一个SSO AuthProvider。
目前看来,咱们的使用方法对多个Organization并没有需求。
新来的SSO用户默认属于所有Team的问题
经阅读代码文件web/frontend/accounts.py 发现在SENTRY_SINGLE_ORGNAZATION=True时会默认设置新注册用户的has_global_access值为True,然后如果有authprovider的话,再用authprovider.default_global_access更新该值;查看auth/helper.py 也发现会在登录和关联身份时,用 authprovider.default_global_access 给用户的has_global_access赋值。
2015年10月23日,将sentry_organizationmember表中 user_id in (35, 66, 67, 69, 71, 72, 73, 74, 77, 78, 81, 83, 84, 85, 86, 88, 89, 91, 92, 95, 96, 97, 98, 99, 100, 102, 103, 105, 107, 108, 109, 110, 112, 113, 114, 115, 117, 118, 119, 120, 122, 124, 125, 126, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 164, 166, 167, 168, 172, 173, 174, 175, 176, 177, 178, 180, 182, 183, 184, 185, 186, 187, 188, 189, 191, 192, 193, 194, 195, 196, 198, 199, 200, 203, 204, 205, 206, 207) 的111位用户的 has_global_access 值改为0,并将sentry_authprovider中id=2,provider=Sankuai的default_global_access字段改为0。
至于如何在SSO插件代码中设置,以便Sentry激活该SSO authprovider时自动将 sentry_authprovider 中 default_global_access字段设置为0,尚须进一步研究。将 orgnazation和authprovider关联的代码在web/frontend/organization_auth_settings.py 但其中并没有涉及default_global_access的内容,也许这个值并不是由authprovider影响的?
Team Admin无权批准人员加入的问题
这一代 Sentry 的权限系统设计的很烂,把 一个人属于哪个Team、一个人有权管理哪个Team混在一起了,无法表达“一个人是TeamA的member,同时是TeamB的admin”的意思。所以我一直倾向于授予较低的权限,但导致了事故。但10月29日由杨明芽发现 Team Admin 无法邀请、批准人员加入本Team,所以写了个后台任务定时批准requests。