
故障现象
2021年1月20日接到通知,要把systemd升级到219-73.tl2.10或以上、并把rsyslog一起升级,以修复/var/log/messages无日志内容的bug。经实验,发现使用yum升级两个软件包之后,systemd-logind的可执行文件也被更新,导致该服务处于原可执行文件已删除的状态,所以我提议,在升级步骤中增加重启systemd-logind服务的动作。在Ansible playbook里,因为不能表达“大于219-73.tl2.10“这种范围型版本号,所以就明确指定systemd的版本为当前yum能自动安装到的最新版本219-78.tl2.3
2月1日由同事执行更新操作之后,大部分节点都正常工作,但有两台发生重启事故,另有一台上的 35777 systemd-login进程占内存高达4~6G。这三台恰好是一组elasticsearch的三台master节点,均为C8机型,即16G内存的kubernetes容器。

检查修复
我尝试重启剩余的这台的system-logind,发现新进程3851号仍然占6G内存。查看/proc/3851/smaps,该区域为heap;用pmap命令查看,显示为[ anon ]。对比正常服务器的同一个内存区域,才244K而已。
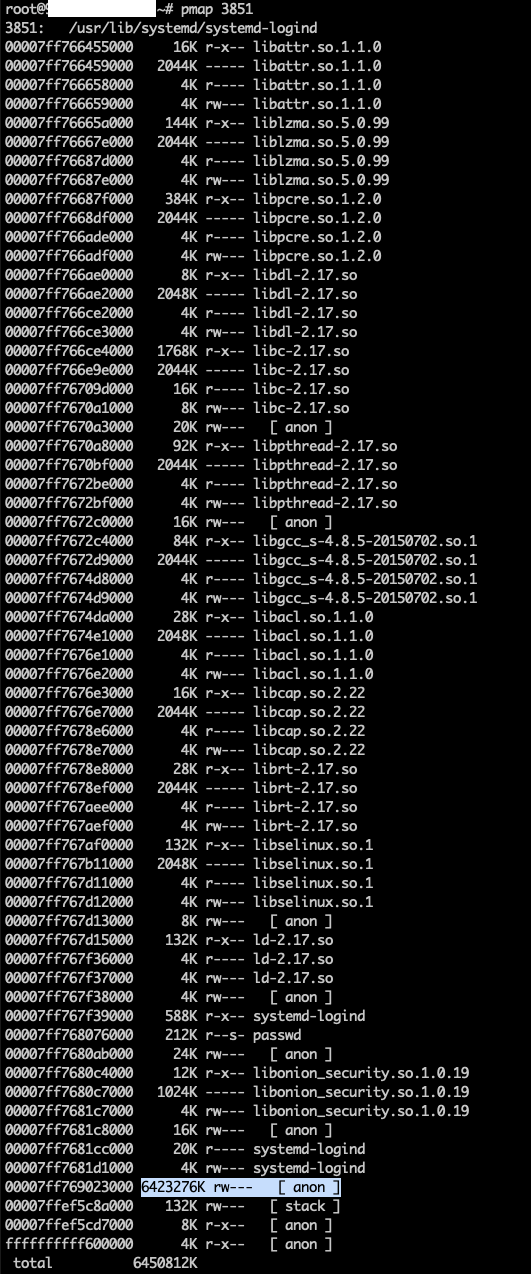
检查三台故障机及其宿主机的日志,发现大量oom记录,其中重启的两台所属宿主机的kubelet也发生故障重启:Feb 1 18:43:50 TENCENT64 kubelet: panic: runtime error: invalid memory address or nil pointer dereference
先gcore一份保留故障现场。
由于操作系统组同事不登录上来观察,仅提供重启进程等建议,我只好自己做检查。
根据建议,检查了dbus服务(dbus-daemon进程),发现也是可执行文件被删除的状态。检查yum日志,发现在去年6月升级了dbus包,但是服务进程是3月5日启动的,也就是升级包的时候并没有重启这个服务。
再次尝试重启systemd-logind,新进程14278号,发现用内存VmPeak: 5270484 kB;但是过了一会儿再观察,发现增加到了VmPeak: 6599828 kB。这说明内存的增长是一个过程,虽然增长比较快,但并不是一下子就6G的。于是我决定strace一下它。
先关闭systemd-logind服务。使用命令strace -ff -s 1000 -p 1挂在systemd主进程上做跟踪,并用-o参数把多个进程的跟踪记录分别写在文件里。然后启动systemd-logind服务。这样,strace可以跟踪到 1号进程clone+execv执行systemd-logind的瞬间,以及systemd-login最开头的行为。
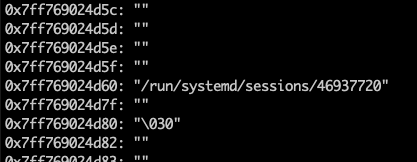
检查systemd-login的strace记录,发现大量访问 /run/systemd/session/ 目录下面文件的动作。检查该目录,发现大量残留文件。
搜索,发现 https://www.jianshu.com/p/343a072e2521 、https://github.com/systemd/systemd/issues/1961 等内容,遂决定用systemctl stop命令清理这些残留的session scope。清理之后再重启systemd-logind服务,恢复正常。
为了验证这个问题,再次拿出之前的gcore,查看指定地址,发现大部分数据为0,个别位置稀稀拉拉的确实发现一些/run/systemd/session/下面的文件名等字符串,但是浓度极低,缺乏作为线索的价值。
原因分析
查看/run/systemd/session/下面残留的session文件,发现绝大部分都有SERVICE=crond这一行。检查crontab发现,腾讯内部常用的山寨启动服务和山寨看守进程的方式(即在cron里ps查看,如果进程消失就再次启动)导致了elasticsearch的java进程被计入user session。在219版本systemd的logind.conf配置文件里,KillUserProcess默认值为no(注意systemd后续某版本的默认值变成了yes!!!),man logind.conf没多说什么,但是新版本的man logind.conf说设置KillUserProcess=no会导致 user session scope保持在abandon状态,即我们遇到的这种症状。
所以,山寨的看守进程方式,是导致本次故障的根本原因。这种方式不仅内部,连对外服务的腾讯云也有类似问题:https://www.jianshu.com/p/343a072e2521
这里有一篇关于关于cgroup v1 empty notification在容器内失灵的邮件,提到了session回收的机制:https://listman.redhat.com/archives/libvir-list/2014-November/msg01090.html
使用dbus-monitor和strace观察的时候,dbus-monitor可以观察到session scope的UnitRemoved、session的SessionRemoved等事件在dbus上传输;不过此时挂上strace去观察systemd-logind却往往是正常工作的状态。
单独使用 dbus-monitor 但不用strace,发现残留的session后,再去查阅dbus-monitor的记录,发现在SessionRemoved消息之后出现的
path=/org/freedesktop/login1/user/_0; interface=org.freedesktop.DBus.Properties; member=PropertiesChanged
这个消息的消息体特别巨大,内含近六百个session的编号,应该是全量更新该用户下属的session列表,而不是差量更新。所以我认为session残留其实是个旧数据累积导致的systemd-logind的性能雪崩问题。
此外,dbus-monitor还观察到PolicyKit (polkit.service)服务启动的时候也有大量的session信息在dbus上传输,polkit服务启动后迟迟不能就绪。这个服务如不就绪,会导致systemctl重启服务的动作失败、reboot等命令也可能失败(https://github.com/systemd/systemd/blob/main/src/systemctl/systemctl-start-unit.c#L254 调用polkit_agent_open_maybe()函数)。这样就产生里一个循环依赖:清理残留session需要systemctl命令,systemctl命令需要polkit授权,而polkit也被残留的session给害死了无法正常工作。如果发生这种情况,就只好手工删除session文件,残留一些其他数据在内存里(参考https://github.com/systemd/systemd/blob/main/src/login/logind-session.c#L745)并借助外部机制进行整机重启。
另外,在大量执行systemctl stop session-XXX.scope的时候,也会给systemd-logind带来压力,因为每次开始或者结束session,都会把session号码写入UID对应的 /run/systemd/users/{uid} 文件内
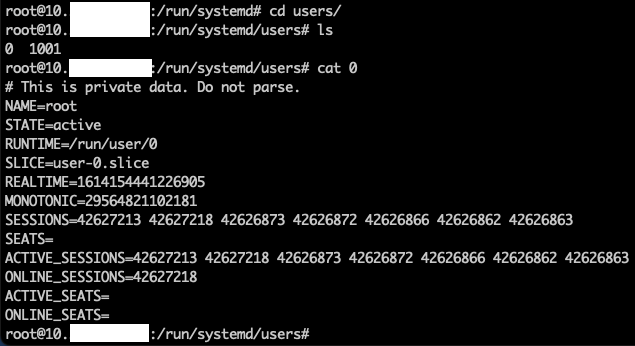
每次变动都会导致这个文件全量覆写,代价也是很高昂的。在残存的session极多的情况下,很难缓过劲来。使用systemctl stop修复的耗时甚至会超过使用重启方法修复的耗时。
————————
另外两台因为oom整机重启, /run/ 是systemd管理的tmpfs,重启后内容丢失,躲过一劫。
经同事提醒,在另一台服务器上虽然也是用crond启动后台服务,但是却没有发生类似症状。我检查发现,该服务器上java进程所属的cgroup是system.slice/crond.slice ,继而发现其/etc/pam.d/password-auth文件被替换过,从一个包含pam_systemd.so的配置文件,变成了指向password-auth-ldap文件的符号链接。因为crond在变换执行身份的时候没有经过pam_systemd.so 所以也不会被systemd-logind 记录,不产生session,也自然不会有残留。这种更改误打误撞让这批服务器躲过一劫。但是由于公司内软件山寨的安装方式,到底谁改了这个配置文件、password-auth-ldap文件属于哪个软件,我费了很大劲才打听到是一个内部用于管理ssh登录权限的软件。
触发条件总结
- /etc/pam.d/crond遵守系统默认值,即:包含pam_systemd.so,就会把crond产生的子进程放到user session里去。具体到腾讯内的具体情况,如果安装了那个ssh登录权限管理软件,则可侥幸躲过一劫。
- cron任务比较频繁的时候,会产生大量的Session新建和销毁消息,伴随全量更新,对logind造成较大压力;在其未能处理完毕的时候下一次更新数据又来了,造成累积
改进建议
- 自研软件包也应该做成RPM包,实现安装过程标准化、文件可追踪(rpm –list)可验证(rpm –verify),可以追查哪个文件属于哪个软件包(rpm –query –file)
- 服务启动应该托管给systemd作为service unit,由systemd负责进程的启动、故障重启和关闭
- 应弃用容器作为服务器这种做法,规避cgroup v1 empty notification的问题
systemd的好处有:
- 通过cgroup可以知道Which Service Owns Which Processes,确保关闭服务时没有泄漏子进程请(参见《supervisor泄漏进程案例分析》);
- 通过SIGCHLD实现低代价(无额外进程vs. bash+ps+grep+grep)、实时(vs. crond的一分钟粒度)监测进程存活性
- 通过service unit file的声明式写法,使服务脱离用户级运行环境、脱离user.slice、system.slice/sshd.service和system.slice/crond.service的cgroup,拥有自己独立干净的启动条件,避免受到用户环境变量、rlimit等设置的干扰和传染
附清理方法:
必须判断进程是否存在,然后再清理残留的session scope,否则会误关闭进程。比如:# grep name=systemd /proc/$(pidof java)/cgroup 1:name=systemd:/kubepods/pod480ee9e9-5ec9-11ea-bf78-6c0b84d57dd5/2b34cb158d5fa1db6f17d9099c3b5314f67223f6aeb71c3c6cedbafd84df0b24/user.slice/user-1002.slice/session-47639512.scope
这里java进程的cgroup是session-47639512.scope ,则/run/systemd/sessions/47639512 文件不应该被删除,也不应该执行 systemctl stop session-47639512.scope
然而,从session入手,推断其下属进程是比较困难的。
可以用下列命令判断,session文件存在但是cgroup已经消失的情况,以及cgroup存在但是内部不包含进程这两种情况,然后输出其路径或执行systemctl stop清理:cd /sys/fs/cgroup/systemd/user.slice/; find /run/systemd/sessions -type f | xargs -n1 -i bash -c 'source {} 2>/dev/null ; DIR=user-$(getent passwd $USER|cut -d: -f3).slice/$SCOPE; ( test ! -d $DIR || test ! "cat $DIR/tasks" )&& echo stop $SCOPE || echo keep $DIR'
如果在C8机型上运行,上述cd的路径应参考/proc/1/cgroup的内容,修正为
`/sys/fs/cgroup/systemd/kubepods/pod{POD号}/{容器号}/user.slice/